本文共 4049 字,大约阅读时间需要 13 分钟。
biostarhandbook(一)分析环境和数据可重复
2017/10/18/11:00第一版本笔记,主要更新了生物信息要用那些基本技能和电脑配置简单说明,以及如何在虚拟机器上安装bioconda
2017/10/18/12:30第二版笔记,增加虚拟机配置 2017/10/18/13:05 第三版笔记,增加文件结构 2017/10/19/10:30 第四版笔记, 增加如何用xshell连接虚拟机内部系统 2017/10/20/08:09 第五版笔记,增加线下辅导部分。
生物信息的基本技能
- 数据管理: 也就是你如何获取所需数据,以及如何存放管理这些数据。尤其是后期数据越来越多的时候,混乱的管理会导致极大的效率降低和不可重复的结果产生。
- 初步数据分析: 就是利用不同软件把格式A转换称格式B,其中如果缺少必要的工具,你还得自己写工具。这就是为什么你要学Linux和脚本语言
- 数据解释: 软件只会给你一堆数据,如何赋予数据意义,这就是涉及到统计,生物等多学科的交叉。
如何解决所有问题
这个问题对于初学者而言,非常重要,当然我觉得更加重要的问题是:
如何发现自己真正的问题。
是的,大部分人是意识不到自己到底有什么问题,我遇到的最多的提问就是给我发了一张截图,期望我能像福尔摩斯一样根据一些小小的线索推测背后的原因。
我当然有这个能力,毕竟我是自学过来的,但是我不会去推测。我不能动你要动的脑子,既浪费我的时间,也浪费我的时间。
因此,搞不清楚如何提问才是初学者的最大的问题。因此先去买一本《如何提问》读几遍。
搞生信要什么样的电脑
Biostar handbook的前几周课程可以现在虚拟机上面运行,主要是熟悉Linux操作和部署工作环境。
由于之前安装Docker需要安装Hyper-V,所以演示基于微软的Hyper-V, VirtualBox和VM也可用。
先去下载Ubuntu的安装ISO文件
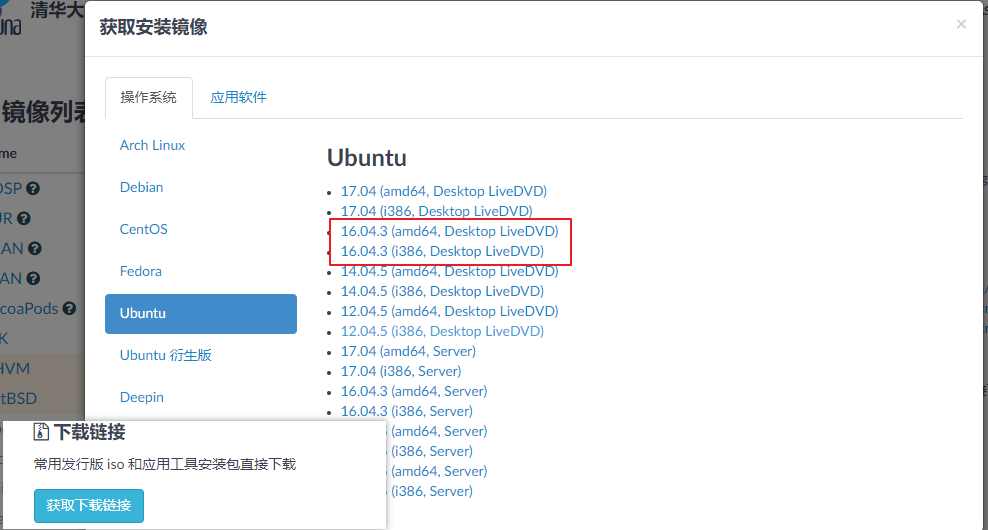
然后查看百度经验
重点是:选择合适内存大小(>4G)和虚拟机文件存放位置。第一代还是第二代虚拟机影响不大,后续要么在硬盘上装Linux要么就用Windows。
关于网络设置原理推荐看这篇文章:后续实际分析的时候则是需要一台小型服务器,或者是一台高性能的PC,这部分根据组里的经费,配置越高越好。内存至少16G起步,64G比较合适,128G大部分的处理再也不是你的问题了。
如何配置你的电脑
以下操作都在虚拟机中完成,避免因为不熟练祸害到真实世界。
后续的数据分析主要熟悉多种多样的软件,因此第一个问题就是如何运行软件。
- 二进制包可以直接运行,(需要设置环境变量)
- 源代码需要编译(有难度)
- java, python, perl用来解释下载的对应代码
当然初学者我推荐用conda(Linux),或homebrew(Mac OS).因此只要如下三步
- 打开虚拟机
- 安装conda,并且加载bioconda
- 安装软件
打开虚拟机
打开虚拟机之后,请尽量用 ctrl+alt+F1~F6切换到这如下这种黑乎乎的界面,后续我们的操作尽量去便面用到图形界面。
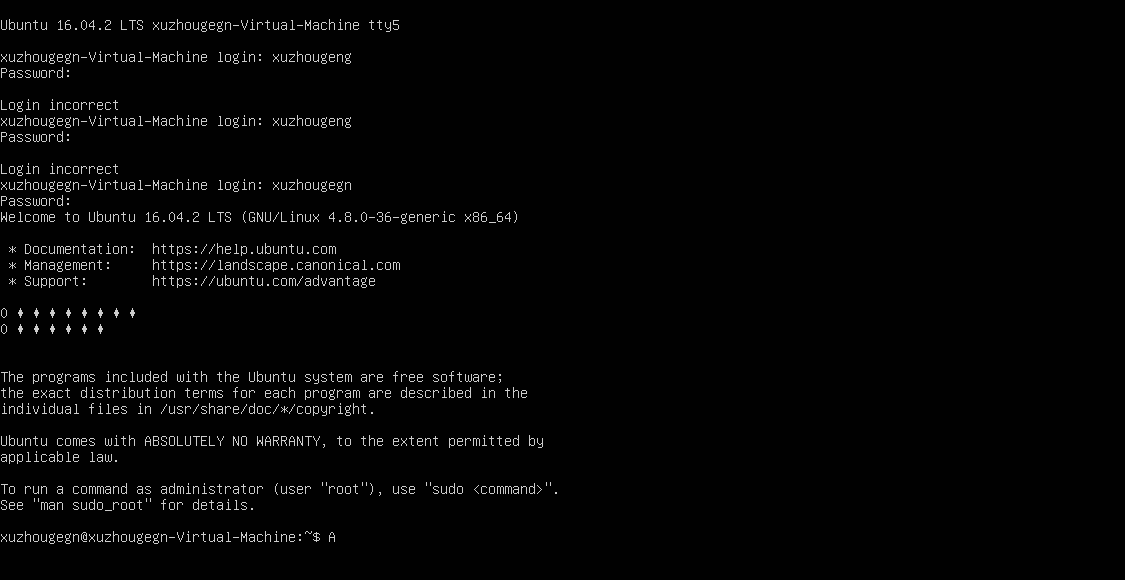
第一: 图形界面操作在虚拟机下感觉会卡
第二: 图形界面不是Linux所必须 第三: 服务器也是黑乎乎确保ping -c 3 baidu.com的结果如下:
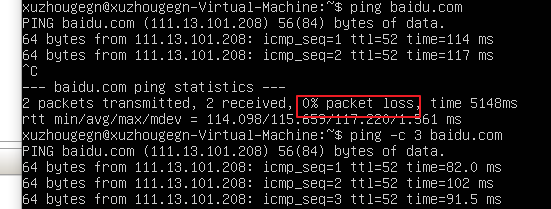
这一步是保证网络畅通。之后我们需要配置Ubuntu的包管理镜像,采用国内快速的镜像源, 偷懒的做法是在设置中的软件和更新里面点点鼠标自动选择最快的服务器。

之后你软件会进行自动地一些更新。但是最优雅的方法就是,用如下的命令。
# 不要复制,请确保自己选择合适的镜像sudo sed -i 's/archive.ubuntu.com/mirrors.ustc.edu.cn/g' /etc/apt/sources.listsudo apt-get updatesudo apt-get upgrade
后续的操作我们都不会继续用到虚拟机的图形界面了,图形太耗资源了
如何优雅的使用虚拟机
微软的Hyper-V的联网方式有:外部,内部和专用三种。。
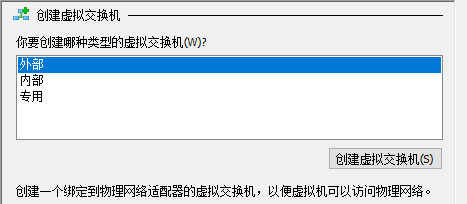
其中外部就是说安装的虚拟机和宿主机处在同一个网络下,你需要为他配置好IP地址,你可以通过ifconfig获取目前的IP.
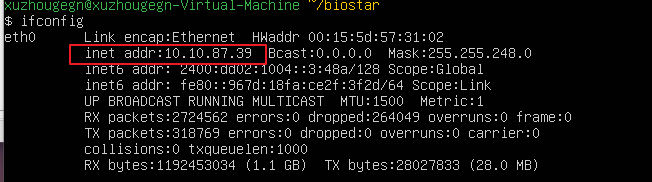
随后,我们就可用利用xshell,进行连接。
Xshell 是一个强大的安全终端模拟软件,它支持SSH1, SSH2, 以及Microsoft Windows 平台的TELNET 协议。Xshell 通过互联网到远程主机的安全连接以及它创新性的设计和特色帮助用户在复杂的网络环境中享受他们的工作。Xshell 是一个强大的安全终端模拟软件,它支持SSH1, SSH2, 以及Microsoft Windows 平台的TELNET 协议。Xshell 通过互联网到远程主机的安全连接以及它创新性的设计和特色帮助用户在复杂的网络环境中享受他们的工作。
首先看看宿主机能否ping通虚拟机中Linux。
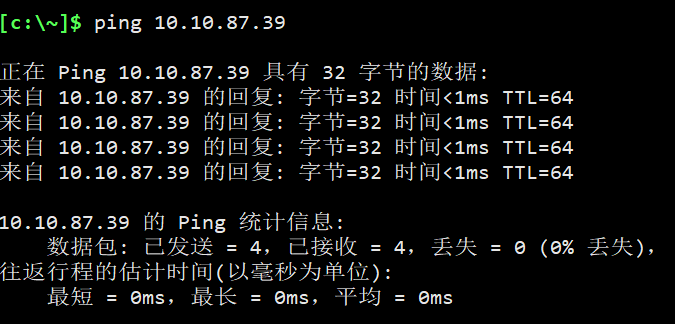
其次ping通之后,还要在Ubuntu中安装openssh-server这样才能保证用户能够访问主机
sudo apt-get install openssh-server# checkps -e | grep ssh

用xshell访问虚拟机,
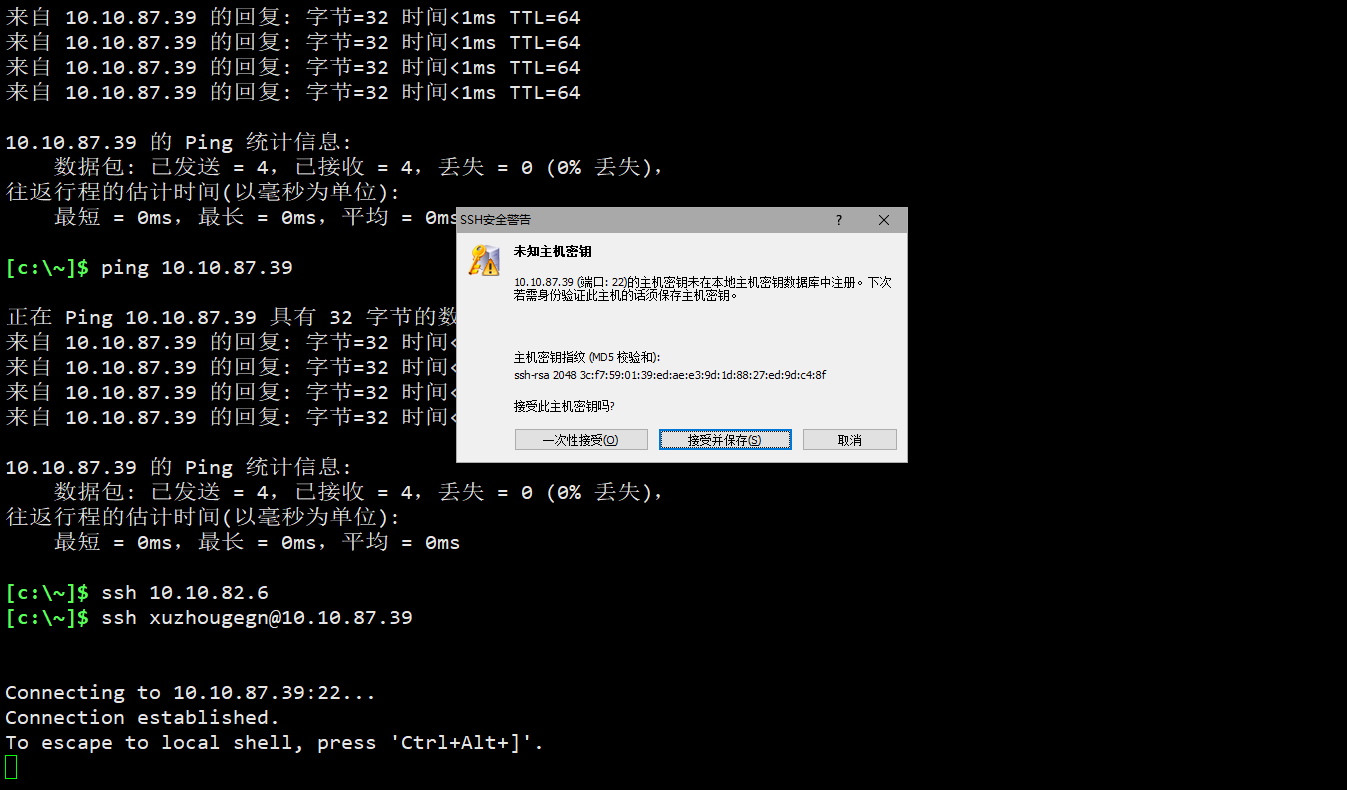
在xshell下使用biostar handbook提供的终端配置
wget http://data.biostarhandbook.com/install/bash_profile.txtcat bash_profile.txt >> ~/.bash_profilewget http://data.biostarhandbook.com/install/bashrc.txtcat bashrc.txt >> ~/.bashrcsource ~/.bash_profile
以上便是系统配置部分。
下载conda
conda,我们使用的清华镜像源的miniconda, 这个时候就只能用ctrl+shift+F7切换会图形界面,然后以之前获取Ubuntu下载链接的相同方式获取miniconda. 如果清华镜像源搞不定,还有中科大,阿里,163等多个镜像源等着你,不要在一棵树上吊死

mkdir srccd src# 下载镜像wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/Miniconda3-4.3.27-Linux-x86_64.sh# 安装bash Miniconda3-4.3.27-Linux-x86_64.sh# 后续就不断的yes就行了。# 配置conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/conda config --set show_channel_urls yesconda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/
注意: 经常有人提问,访问清华镜像源出现404或503等错误,不知道如何解决。我目前的建议就是,自己去 手动下载安装包,然后在miniconda3进行解压缩。
conda install指令做的事情无非也就是先去下载,然后解压缩,只不过核心在于自动解决依赖关系,手动解压缩需要自己解决依赖关系。(我感觉这样说也很难懂) 后续我们的工作都会在conda提供的工作环境中进行
conda create -y --name bioinfo python=2source activate bioinfo
source适用于启动工具环境的,请查阅source的工作原理。
安装课程所需要的所有软件
curl http://data.biostarhandbook.com/install/conda.txt | xargs conda install -y

文件结构:强迫症的解药,所有人的良方
实不相瞒,如何设计一个优秀的文件结构是一个很乏味,但是对非常重要的工作,所以我建议你先去读读一篇发在plot上的论文.
然后再看看别人的经验之谈
这个内容在后续数据模块才会强调,但是目前比较重要的是
- 请把源代码放到
~/src中 - 请把二进制文件放到
~/bin中 - 请把参考基因组如下方式存放
genome├── 物种名│ ├── 版本号│ │ ├── readme.txt│ │ ├── Annotation # 存放注释│ │ │ ├── Ahalleri_264_v1.1.annotation_info.txt│ │ │── BLAST #存放BLAST│ │ │── HISTA2 # 存放HISAT2的索引│ │ │── BWA # 存放BWA的索引│ │ │── Sequence # 存放基因组FASTA文件
这部分的重点:
- 如何使用虚拟机,将来是如何在电脑上安装Linux
- 如何运行命令
- 环境变量
- conda的使用,以及conda的工作环境
- 规划文件结构
给自己打个广告, 上海地区提供线下biostar handbook课程辅导,收费是100元/小时,有需求可以简信我。
有些问题只能线下才能更好地解决。总觉得这样卖时间还是便宜了。
转载地址:http://kniga.baihongyu.com/